
Generative AI: A new Gold Rush for software engineering innovation
7 min read
Head over to our on-demand library to view sessions from VB Transform 2023. Register Here
E=mc^2 is Einstein’s simple equation that changed the course of humanity by enabling both nuclear power and nuclear weapons. The generative AI boom has some similarities. It is not just the iPhone or the browser moment of our times; it’s much more than that.
For all the benefits that generative AI promises, voices are getting louder about the unintended societal effects of this technology. Some wonder if creative jobs will be the most in-demand over the next decade as software engineering becomes a commodity. Others worry about job losses which may necessitate reskilling in some cases. It is the first time in the history of humanity that white-collar jobs stand to be automated, potentially rendering expensive degrees and years of experience meaningless.
But should governments hit the brakes by imposing regulations or, instead, continue to improve this technology which is going to completely change how we think about work? Let’s explore:
Generative AI: The new California Gold Rush
The technological breakthrough that was expected in a decade or two is already here. Probably not even the creators of ChatGPT expected their creation to be this wildly successful so quickly.
Event
VB Transform 2023 On-Demand
Did you miss a session from VB Transform 2023? Register to access the on-demand library for all of our featured sessions.
The key difference here compared to some technology trends of the last decade is that the use cases here are real and enterprises have budgets already allocated. This is not a cool technology solution that is looking for a problem. This feels like the beginning of a new technological supercycle that will last decades or even longer.
>>Follow VentureBeat’s ongoing generative AI coverage<<
For the longest time, data has been referred to as the new oil. With a large volume of exclusive data, enterprises can build competitive moats. To do this, the techniques to extract meaningful insights from large datasets have evolved over the last few decades from descriptive (e.g., “Tell me what happened”) to predictive (e.g., “What should I do to improve topline revenue?”).
Now, whether you use SQL-based analysis or spreadsheets or R/Stata software to complete this analysis, you were limited in terms of what was possible. But with generative AI, this data can be used to create entirely new reports, tables, code, images and videos, all in a matter of seconds. It is so powerful that it has taken the world by storm.
What’s the secret sauce?
At the basic level, let’s look at the simple equation of a straight-line y=mx+c.

This is a simple 2D representation where m represents the slope of the curve and c represents the fixed number which is the point where the line intersects the x-axis. In the most fundamental terms, m and c represent the weights and biases, respectively, for an AI model.
Now let’s slowly expand this simple equation and think about how the human brain has neurons and synapses that work together to retrieve knowledge and make decisions. Representing the human brain would require a multi-dimensional space (called a vector) where infinite knowledge can be coded and stored for quick retrieval.
Imagine turning text management into a math problem: Vector embeddings
Imagine if every piece of data (image, text, blog, etc.) could be represented by numbers. It is possible. All such data can be represented by something called a vector, which is just a collection of numbers. When you take all these words/sentences/paragraphs and turn them into vectors but also capture the relationships between different words, you get something called an embedding. Once you’ve done that, you can basically turn search and classification into a math problem.

In such a multi-dimensional space, when we represent text as a mathematical vector representation, what we get is a clustering where words that are similar to each other in their meaning are in the same cluster. For example, in the screenshot above (taken from the Tensorflow embedding projector), words that are closest to the word “database” are clustered in the same region, which will make responding to a query that includes that word very easy. Embeddings can be used to create text classifiers and to empower semantic search.
Once you have a trained model, you can ask it to generate “the image of a cat flying through space in an astronaut suit” and it will generate that image in seconds. For this magic to work, large clusters of GPUs and CPUs run nonstop for weeks or months to process the data the size of the entire Wikipedia website or the entire public internet to turn it into a mathematical equation where each time new data is processed, the weights and biases of the model change a little bit. Such trained models, whether large or small, are already making employees more productive and sometimes eliminating the need to hire more people.
Competitive advantages
Do you/did you watch Ted Lasso? Single-handedly, the show has driven new customers to AppleTV. It illustrates that to win the competitive wars in the digital streaming business, you don’t need to produce 100 average shows; you need just one that is incredible. In the world of generative AI, this happened with OpenAI, which had nothing to lose as it kept iterating and launching innovative products like GPT-1/2/3 and DALL·E. Others with deeper pockets were probably more cautious and are now playing a catchup game. Microsoft CEO Satya Nadella famously asked about generative AI, “OpenAI built this with 250 people; why do we have Microsoft Research at all?”
Once you have a trained model to which you can feed quality data, it builds a flywheel leading to a competitive advantage. More users get driven to the product, and as they use the product, they share data in the text prompts, which can be used to improve the model.
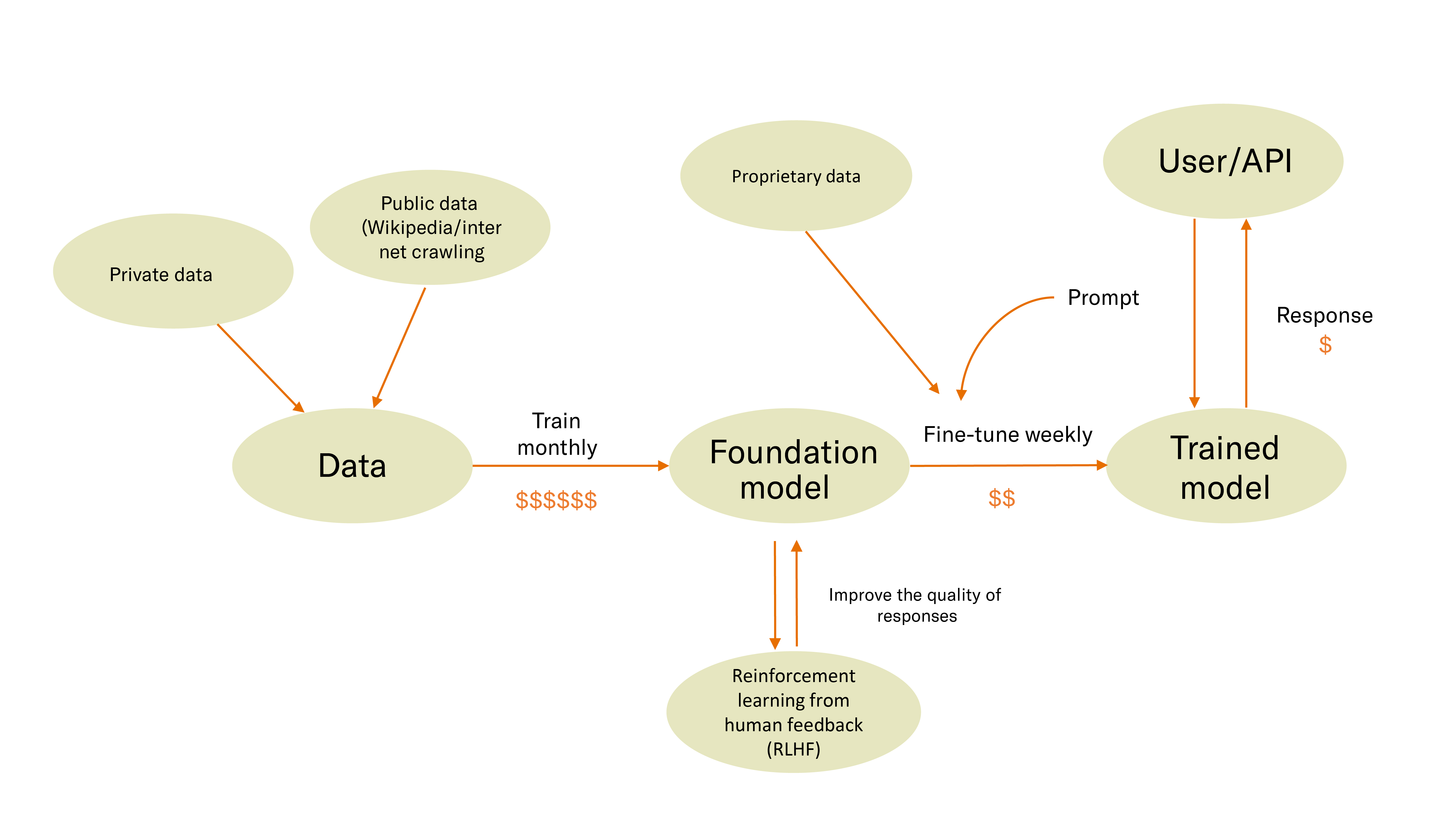
Once the flywheel above of data -> training -> fine-tuning -> training starts, it can act as a sustainable competitive differentiator for businesses. Over the last few years, there has been a maniacal focus from vendors, both small and large, on building ever-larger models for better performance. Why would you stop at a ten-billion-parameter model when you can train a massive general-purpose model with 500 billion parameters that can answer questions about any topic from any industry?
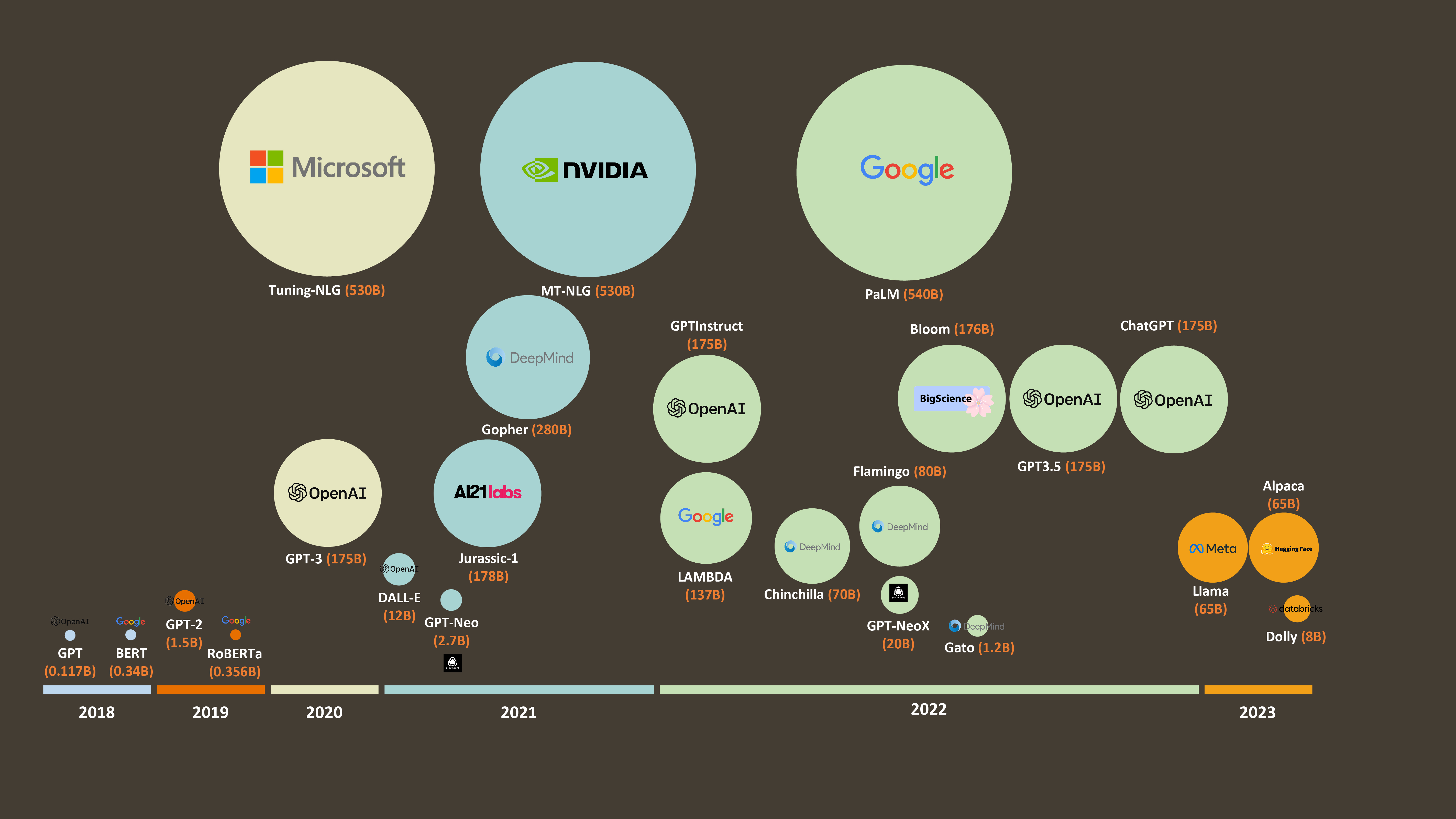
There has been a realization recently that we might have hit the limit of productivity gains that can be achieved by the size of a model. For domain-specific use cases, you might be better off with a smaller model that is trained on highly specific data. An example of this would be BloombergGPT, a private model trained on financial data that only Bloomberg can access. It is a 50 billion-parameter language model that is trained on a huge dataset of financial articles, news, and other textual data they hold and can collect.
Independent evaluations of models have proved that there is no silver bullet, but the best model for an enterprise will be use-case specific. It may be large or small; it may be open-source or closed-source. In the comprehensive evaluation completed by Stanford using models from openAI, Cohere, Anthropic and others, it was found that smaller models may perform better than their larger counterparts. This affects the choices a company can make regarding starting to use generative AI, and there are multiple factors that decision-makers have to take into account:
Complexity of operationalizing foundation models: Training a model is a process that is never “done.” It is a continuous process where a model’s weights and biases are updated each time a model goes through a process called fine-tuning.

Training and inference costs: There are several options available today which can each vary in cost based on the fine-tuning required:
- Train your own model from scratch. This is quite expensive as training a large language model (LLM) could cost as much as $10 million.
- Use a public model from a large vendor. Here the API usage costs can add up rather quickly.
- Fine-tune a smaller proprietary or open-source model. This has the cost of continuously updating the model.
In addition to training costs, it is important to realize that each time the model’s API is called, it increases the costs. For something simple like sending an email blast, if each email is customized using a model, it can increase the cost up to 10 times, thus negatively affecting the business’s gross margins.
Confidence in wrong information: Someone with the confidence of an LLM has the potential to go far in life with little effort! Since these outputs are probabilistic and not deterministic, once a question is asked, the model may make up an answer and appear very confident. This is called hallucination, and it is a major barrier to the adoption of LLMs in the enterprise.
Teams and skills: In talking to numerous data and AI leaders over the last few years, it became clear that team restructuring is required to manage the massive volume of data that companies deal with today. While use case-dependent to a large degree, the most efficient structure seems to be a central team that manages data which leads to both analytics and ML analytics. This structure works well not just for predictive AI but for generative AI as well.
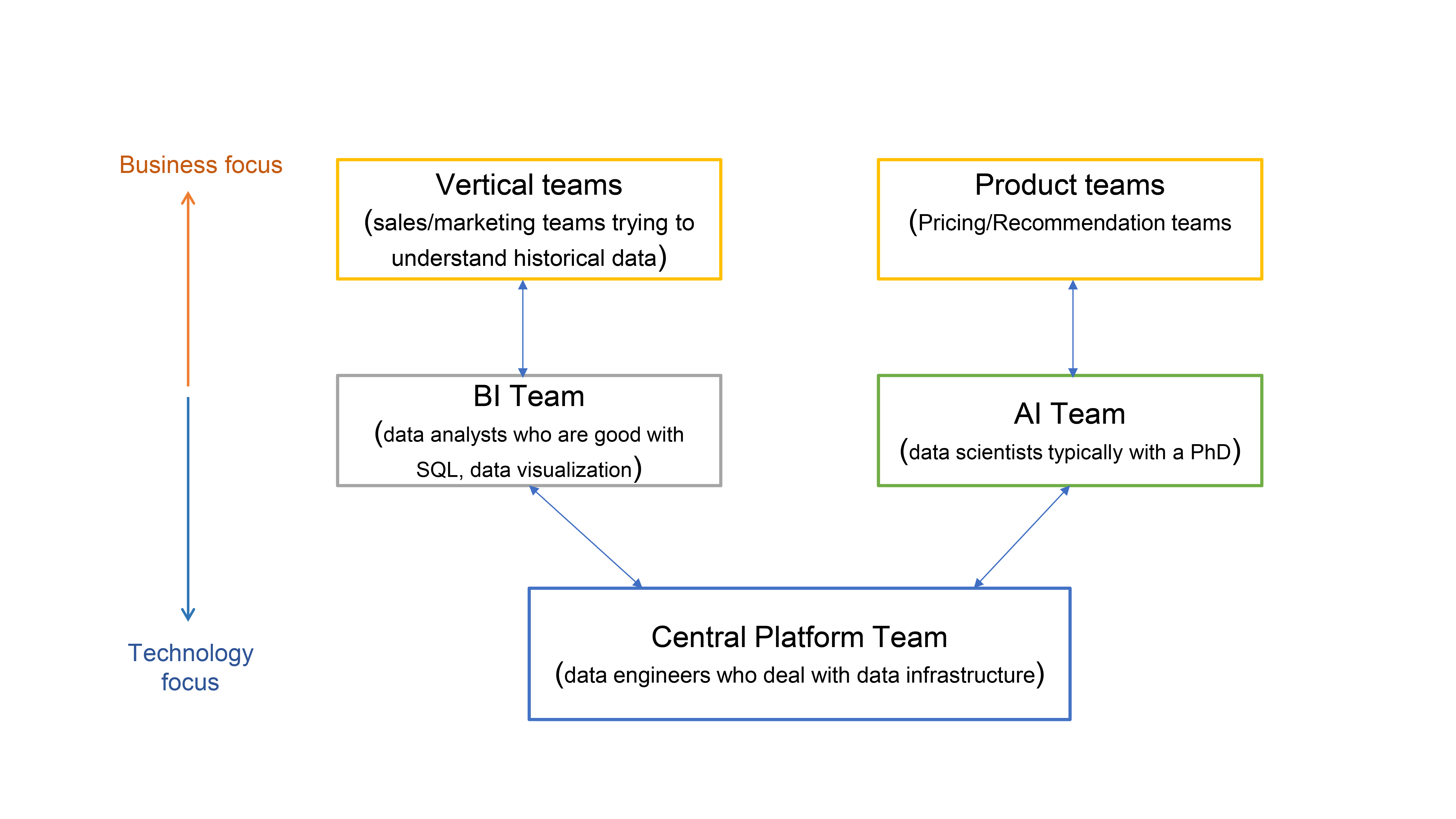
Security and data privacy: It is so easy for employees to share critical pieces of code or proprietary information with an LLM, and once shared, the data can and will be used by the vendors to update their models. This means that the data can leave the secure walls of an enterprise, and this is a problem because, in addition to a company’s secrets, this data might include PII/PHI data, which can invite regulatory action.
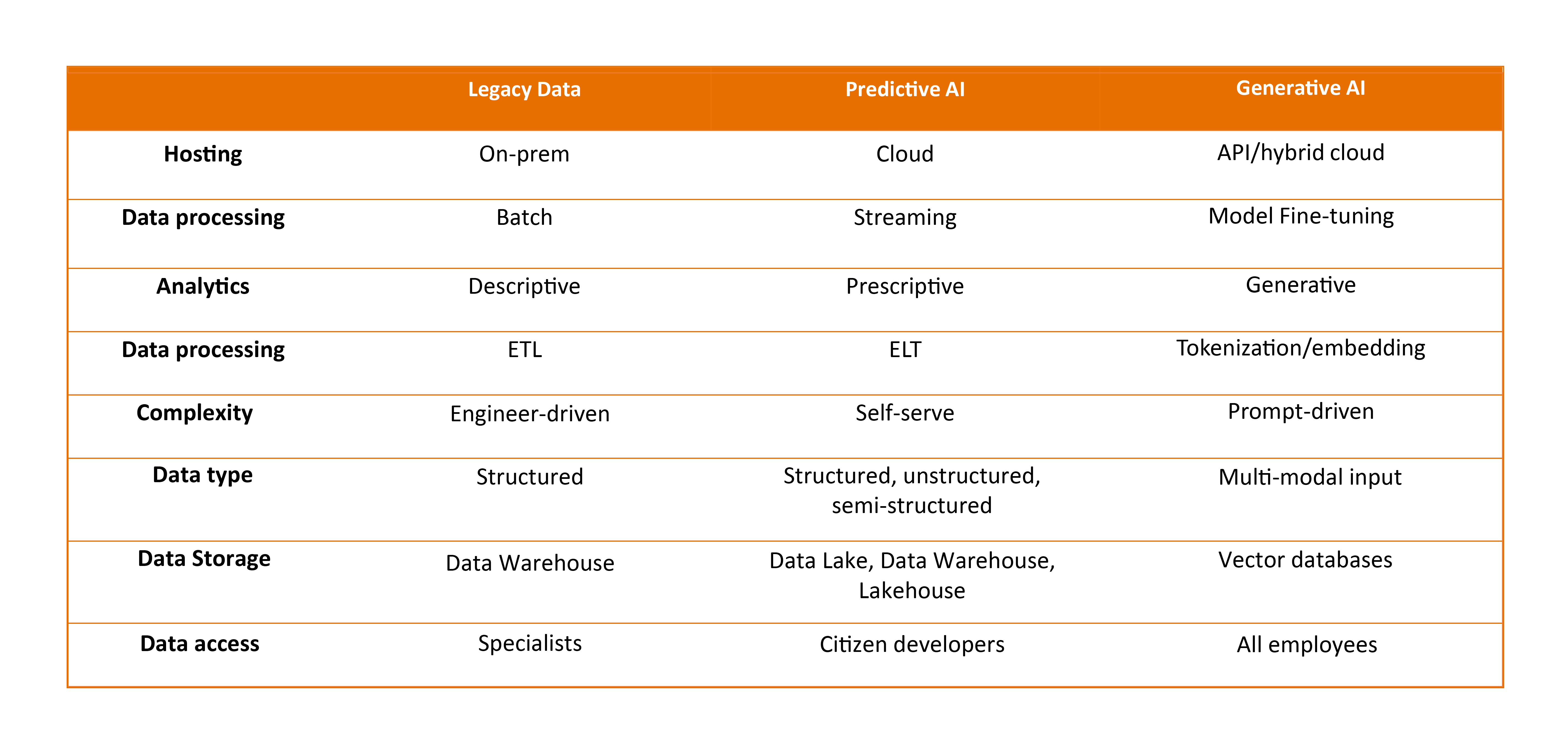
Predictive AI vs. generative AI considerations: Teams have traditionally struggled to operationalize machine learning. A Gartner estimate was that only 50% of predictive models make it to production use cases after experimentation by data scientists. Generative AI, however, offers many advantages over predictive AI depending on use cases. The time-to-value is incredibly low. Without training or fine-tuning, several functions within different verticals can get value. Today you can generate code (including backend and frontend) for a basic web application in seconds. This used to take at least days or several hours for expert developers.
Future opportunities
If you rewound to the year 2008, you would hear a lot of skepticism about the cloud. Would it ever make sense to move your apps and data from private or public data centers to the cloud, thereby losing fine-grained control? But the development of multi-cloud and DevOps technologies made it possible for enterprises to not only feel comfortable but accelerate their move to the cloud.
Generative AI today might be comparable to the cloud in 2008. It means a lot of innovative large companies are still to be founded. For founders, this is an enormous opportunity to create impactful products as the entire stack is currently getting built. A simple comparison can be seen below:

Here are some problems that still need to be solved:
Security for AI: Solving the problems of bad actors manipulating models’ weights or making it so that each piece of code that is written has a backdoor written into it. These attacks are so sophisticated that they are easy to miss, even when experts specifically look for them.
LLMOps: Integrating generative AI into daily workflows is still a complex challenge for organizations large and small. There is complexity regardless of whether you are chaining together open-source or proprietary LLMs. Then the question of orchestration, experimentation, observability and continuous integration also becomes important when things break. There will be a class of LLMOps tools needed to solve these emerging pain points.
AI agents and copilots for everything: An agent is basically your personal chef, EA and website builder all in one. Think of it as an orchestration layer that adds a layer of intelligence on top of LLMs. These systems can let AI out of its box. For a specified goal like: “create a website with a set of resources organized under legal, go-to-market, design templates and hiring that any founder would benefit from,” the agents would break it down into achievable tasks and then coordinate to achieve the objective.
Compliance and AI guardrails: Regulation is coming. It is just a matter of time before lawmakers around the world draft meaningful guardrails around this disruptive new technology. From training to inference to prompting, there will need to be new ways to safeguard sensitive information when using generative AI.
LLMs are already so good that software developers can generate 60-70% of code automatically using coding copilots. This number is only going to increase in the future. One thing to keep in mind though is that these models can only produce something that’s a derivative of what has already been done. AI can never replace the creativity and beauty of a human brain, which can think of ideas never thought before. So, the code poets who know how to build amazing technology over the weekend will find AI a pleasure to work with and in no way a threat to their careers.
Final thoughts
Generative AI for the enterprise is a phenomenal opportunity for visionary founders to build the FAANG companies of tomorrow. This is still the first innings that is being played out. Large enterprises, SMBs and startups are all figuring out how to benefit from this innovative new technology. Like the California gold rush, it might be possible to build successful companies by selling picks and shovels if the perceived barrier to entry is too high.
Ashish Kakran is a principal at Thomvest Ventures.
DataDecisionMakers
Welcome to the VentureBeat community!
DataDecisionMakers is where experts, including the technical people doing data work, can share data-related insights and innovation.
If you want to read about cutting-edge ideas and up-to-date information, best practices, and the future of data and data tech, join us at DataDecisionMakers.
You might even consider contributing an article of your own!

